A Latent Space Odyssey
15 Nov 2018
about
In the aftermath of french people "stealing" code to generate art and making the equivalent of 20 years of PhD salary, I thought it would be a shame not to try it too. The animation is based on 1500 images generated from the pre-trained model by Robbie Barrat. My only contribution was in writing some dodgy code to navigate the latent space of the trained model. For much more impressive animations - recent work (as of november 2018) can be found on twitter .
how it works - a layman's intro
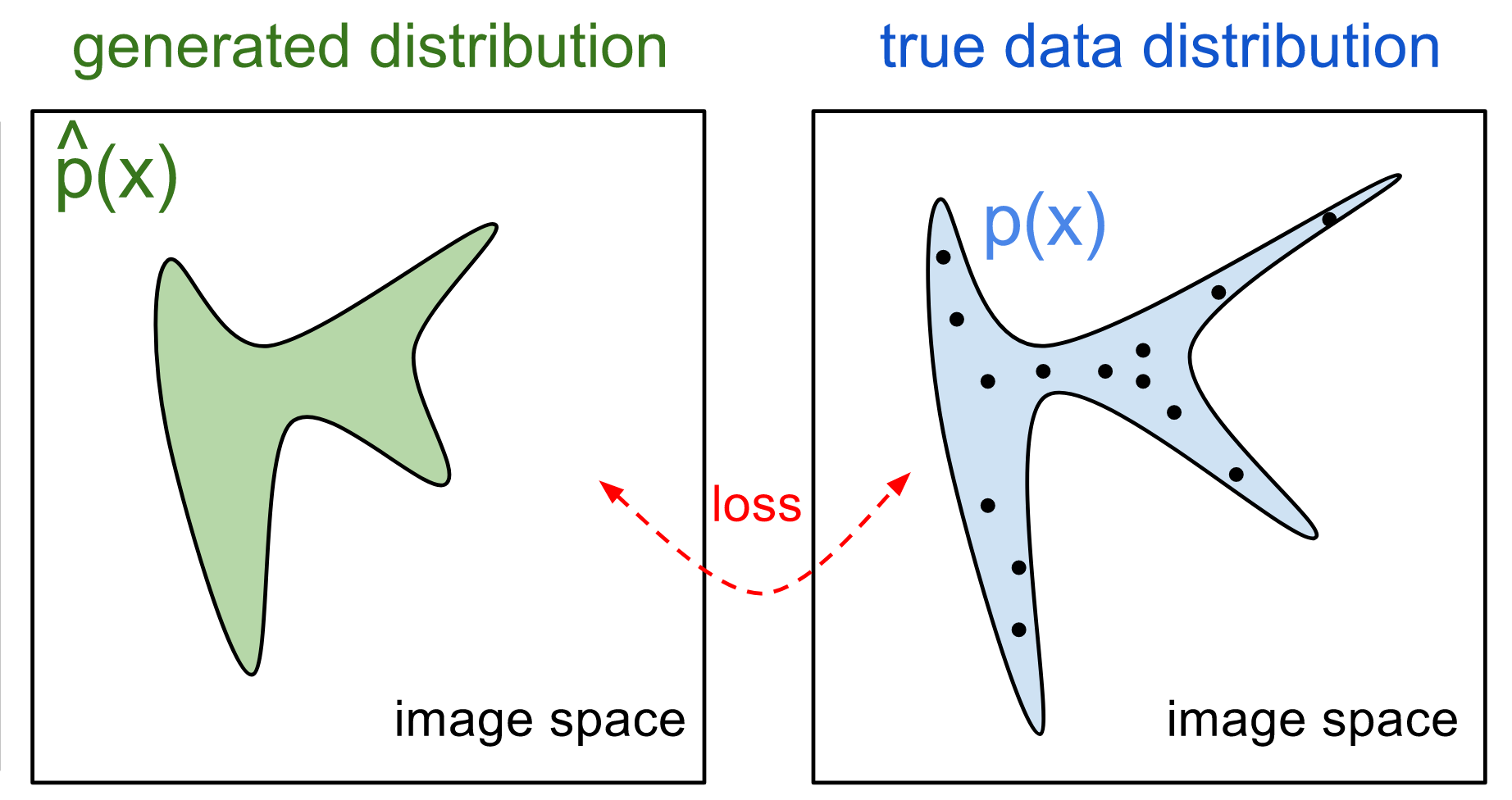
The model used is called a GAN see here for some GAN history see here for an explanation about GANs , short for Generative Adversarial Network. It relies on training a neural network model using a method called adversarial training. The model is trained on some landscape paintings and tries to learn a representation over "all possible" landscape paintings. If you imagine a painting being a point in space, here the model is trying to learn all the possible "landscape painting" points that might exist - even the ones that it has not seen.
This learning process is at the core of how we come to understand the world. For example, we might have seen many dogs in our lives, but we haven't seen all possible dogs. Yet, when we see a dog we're not surprised by the fact that we've never seen this dog before. That's because we have learned some representation over all possible dogs and know that new being fits into a broader category. The term generative refers to our ability to come up with unseen examples from our limited experience (e.g. we could draw an infinite variation of dogs). In short, we generalise about our experiences by trying to link the dots between what we've observed and we can use this to invent new examples.
Another example of "generative thought" is how we're able to imagine a pink elephant even though we'll probably never see one. In this case, we go beyond "linking the dots", and combine ideas (pink + elephant) to create a new one.
Machine Learning researchers are still working on developing more efficient methods to train algorithms that are able to do this well - but we are still quite far from reaching human-like abilities. We require very few examples to construct complex representations over things, whereas our current algorithms might need thousands.
thoughts
Recent conversations have highlighted a fear of Machine Learning models, or Machine Learning generated content replacing artists. The documentary on AlphaGo gives a very vibrant perspective on the “human vs machine” debate. After Lee Sedol, one of the best Go players in the world, was defeated, the Go community responded with excitement about the opportunity of learning more about this still mysterious game. The way I understand this is that people are aware of the importance of art and the role of artists in our society. There is also a growing concern about the omnipresence of technology guiding our lives. Both are legitimate concerns.
My worry is that in asking “Will Artificial Intelligence replace artists?”, the artist becomes the metaphor for the technology, when a better one might be that of the painting brush. If we view art as a creative process rather than as objects, we see that exploring how to use a tool is art - even when the exploration might be widely different from what art exploration has been before.
Another obvious question is who owns the art? After tinkering with the code to generate paths in latent space, it sort of feels mine.
(please dm me for prices)“I never made a painting as a work of art. It's all research.”